Infrastructure TPMs are a different breed
You may be screening us out, even when you need our skills
I’m that weird breed, an Infrastructure Technical Program Manager (iTPM). [To make things easier, in this article I’ll refer to Infrastructure TPMs as iTPM and Sofware TPMs as sTPM. I’ll use the term TPM only when referring to the role more generally.]
[Update, 15 May, 2025: I’ve considered that “software” vs “infra” is the wrong terminology. In infra, much or all of what we deal with is software: Linux, K8s, massive control planes, etc. A better understanding is “applications” vs. “infra.” I’ll leave this blog post as written, but will update my terminology in future writing.]
To explain why, let me first address what’s different about infrastructure in general. I need to set this context, because as I’ll explore going forward, in infrastructure, context is everything, and much of the work we do is in understanding the context. This is not as trivial as it sounds, and has profound implications for how we operate, as explained in this video, that partly inspired my thoughts:
He notes three different common categories of infrastructure work that I will refer to:
- Work you can do immediately when you locate the docs and runbooks.
- Work that requires unbounded context gathering on infrastructures, environments, and services that you didn’t author and that may not be well understood by anybody in your organization. Once the context gathering is done, these often reduce to a series of category 1 tasks.
- More traditional software development tasks, often incremental and focused on internal tools.
In traditional development work (for example, “create a new feature in our app”), the context is usually known. If you’re building software with microservices, you may not need to know much beyond the details of the service interfaces you will connect to. The ambiguity that you as a TPM deal with is usually in the requirements. In infrastructure, nothing makes sense without the greater context, which is where most of the ambiguity lies, at least at the start of any new effort.
iTPMs are “context gatherers”
iTPMs really feel the impact of this, particularly the category 2 items. Work in the category 1 is typically done within DevOps or data center operations teams, and while it may be done in response to, or as part of a larger program, in my experience it’s not something iTPMs are often deeply involved in. Being familiar with those docs and runbooks is a good idea and in some cases, your programs may be responsible for creating them in the first place. Work in category 3 is also usually done within teams. In infrastructure, we are often the users for the software that we create, because the point is to make our services and organizations more scalable by building out better automation, or enabling customer self-service to reduce the need for our involvement. These are often incremental changes or improvements. Sometimes they are driven by a larger program goal, but often they are not. iTPMs may or may not be involved.
Every large scale program I’ve managed as an iTPM has involved a lot of the category 2 work of unbounded context gathering, typically across multiple teams and specialties, usually followed by smaller amounts of category 1 and 3. In many ways it is classic TPM stuff: cross team, ambiguous, and often contentious. It demands great communication skills and ability to grasp concepts you’ve never encountered, and to influence without authority because you will often be asking for work from people far from your own org, or even outside your company. Working on this has been extremely rewarding to me as a TPM, but also as a person in general. I often describe my work saying that “most of the time I have absolutely no idea what I’m doing, and I’m there to find out and drive results anyway.”
This is a major difference between infrastructure and more traditional dev tasks. In infra (and ops), context gathering is the hard part. Most sTPMs can safely expect that their dev teams know the context they need in order to accurately estimate and then execute. It is extremely difficult to estimate or put process around context gathering, but iTPMs have to try to in some way, as that is usually necessary for delivering on a higher-level goal.
An example: building a bespoke AWS region
At one point in my career at AWS I was asked to run a program to design the network infrastructure and configuration for a new region. It was a relatively small program, about a month long. Normally setting up a new region would be a set of “category 1” tasks. We were doing that a few times a year, our runbooks and documentation were ready. We made sure to rotate region build responsibility among our juniors because it was so well defined that even a new person could do most of it without much help. It also provided broad exposure to how our control plane was set up and what all the components were, which was great for a junior or even a new TPM to know. But this was a “special” region, that would exist to allow Amazon to meet some local data residency requirements in one country. The retail org had no desire to spend a lot of money on it, as it would be hosting only enough of their application stack to support the legal requirements, so it was much more minimal than normal.
To do this I had to work across a broad swath of the organization and beyond:
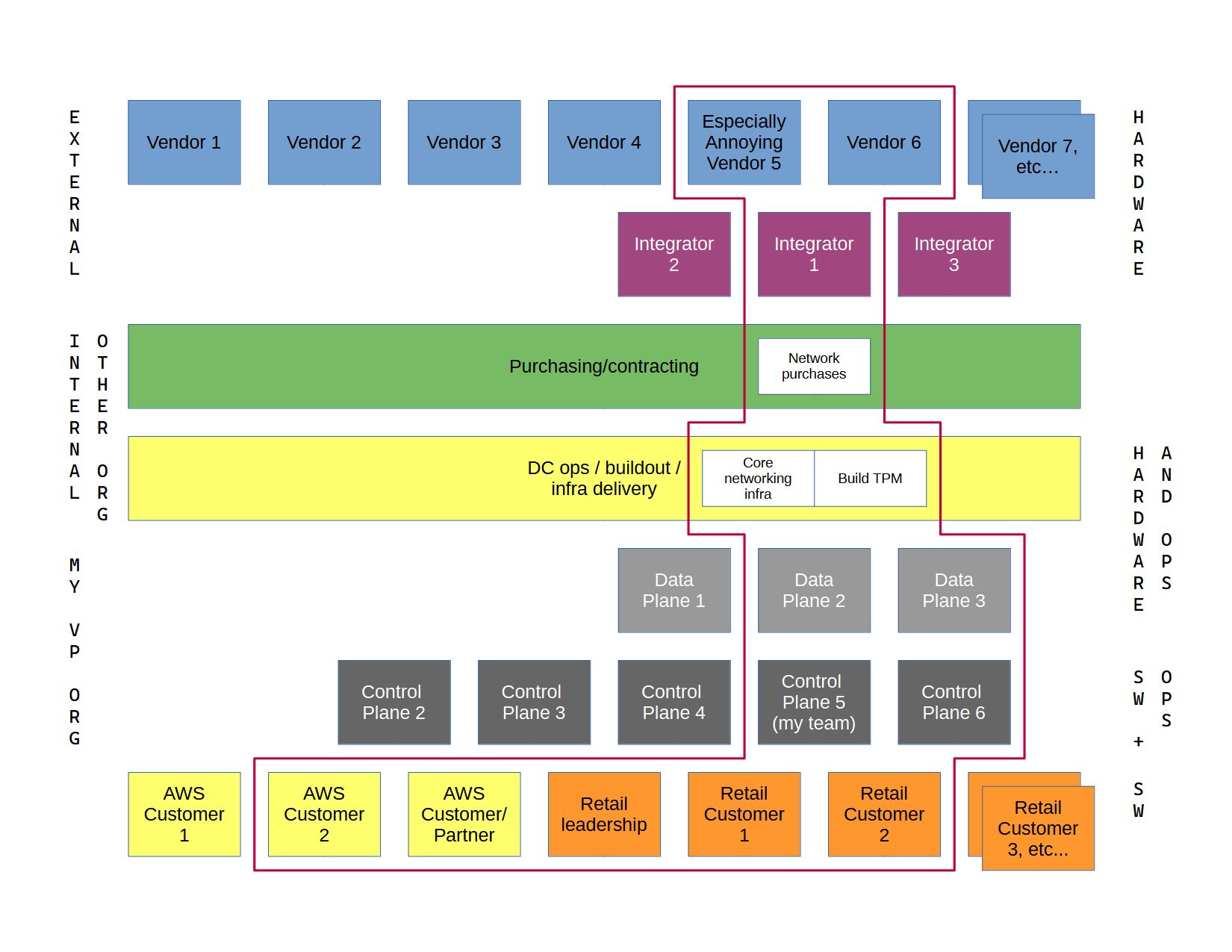
with everybody, not even everybody we normally worked with
but we were involved vertically from hardware acquisition through to
“can an engineer in that region use our CLI reliably?”
I’ll call out a few things: due to the nature of the project and the limited scope, I did not have to worry about all the vendors and components that might be involved in a normal region build as we were only building out some of our services and related infrastructure. I also didn’t have to worry about all the normal AWS customers and partners, because most of them would not be involved. I didn’t even have to worry about much of my own org, either because their pieces would not be involved, or because we had sufficient understanding of them to recognize that the unusual design wouldn’t be an issue and the normal runbooks would apply.
I did have to worry about some Amazon retail teams and senior Amazon retail management, because the project was being done exclusively for them and they were paying for it. That would not be the case in a regular region build. But just figuring out who did and didn’t need to be on the list of stakeholders was a significant amount of context exploration. What specific AWS services would exist in a region designed only to support a handful of retail applications? We didn’t know at the start and that couldn’t be answered until somebody in the retail organization did the analysis so the larger program could move forward, because they didn’t know up-front either.
What did all those teams and services need from us, given the unusual configuration? Nobody knew. Even the teams didn’t know, because they had never considered the question of how to operate in this kind of non-standard environment. How would our data plane behave given the unusual configuration? Unknown. How would we maintain availability to the required SLA given the unusual configuration? We had to figure that out because reduced redundancy was inherent in the design. Which vendors needed to be involved? Thankfully not all, but one of the most difficult ones did. So purchasing (and I’m told, legal) had to be pulled in to deal with them and come up with a bespoke contract for the bespoke region. We were able to use the best of our three integrators to build out the racks and ship them to the site, which simplified things because they were easy to work with. Thankfully I only needed to be involved in this peripherally as we had excellent purchasing and infra delivery orgs. Mostly there would not be changes to the relevant pieces of the control plane or data plane that we owned, but there were minor updates necessary, particularly for reporting, metrics collection and other auxiliary functions that made assumptions about “what does an AWS region always look like” that would not apply in this case.
About halfway through, one of our senior engineers realized that the core planning team for the whole program forgot to include DNS. Yes, it’s always DNS. That had to be fixed, they were extremely pissed at being left out, and we had to tweak our solution a bit to accommodate their needs.
Work on the context gathering and design took about six weeks, though we had sufficient context and confidence about 3 weeks in to commit to a maximum budget. The final budget ended up being lower. Many docs were written and options proposed. Once that was done, pulling together the design all the way through from high-level outline all the way to the details of software, network and rack configuration was trivial. The build out ran about as well as any other region build, meaning it was a matter of cutting tickets to the appropriate teams, then monitoring for status and escalating the occasional roadblock. The hard work wasn’t the build, it was setting ourselves up for a successful build.
Compare that to the kind of program you’ll hear most TPMs talking about, or most common definitions of what a TPM does. Almost all those focus on work in the bottom two rows of my oversimplified org chart. Often an sTPM works entirely in the bottom row, the one that delivers applications to end users, and there is often a product manager/team involved.
We don’t have those!
If you’re a small organization, building exclusively in the cloud, that allows your development teams to manage their own cloud infrastructure and your internal infra consists of an office network, you probably don’t need an iTPM. Most sizable organizations have some. Often they don’t need to extend all the way to the hardware, but you’ll almost always have some kind of teams that manage/develop platforms and/or your cloud provider, to abstract that mess away from most developers.
With more and more companies looking at “cloud repatriation” as a money-saving alternative, you’ll likely see more of us in the coming years.
You’re probably hiring us wrong
TPM hiring usually involves two interviews that can be especially problematic for iTPMs if not managed well: the program/tech review, where you are expected to deep-dive the tech of something you’ve worked on recently, and the system design.
When I joined AWS, this was relatively straightforward for me as an iTPM. I was asked to design a monitoring system for a load balancer (or, as my manager-to-be told me, any network device that has packets going in one side, and then out the other). It sounds trivial if you don’t know much about the space, but gets into a lot of interesting concepts: monitors vs canaries, pull vs. push messaging, failure modes, network latency, storing metrics, creating dashboards and alerts for those metrics, whether, when and for what information is caching appropriate, and what type of caching might be the right choice. Then there’s cost management, capacity, etc. More than enough for a detailed hour-long discussion that could show off my tech chops. That kind of discussion won’t get into API design or what kind of database to use — things that you’d commonly discuss as an sTPM — but those aren’t commonly what iTPMs do!
When I joined Stripe, I had to go through the systems design interview twice because the first interviewer thought I must have been missing something in the question. The second interviewr was a bit more understanding of where I was coming from and allowed me to focus mostly on backend design that was more closely related to things I had worked on recently. But both asked me to design a consumer-facing mobile app. Why? While working there, I found that was one of the “standard questions asked of TPMs,” “we assume it’s the space most people are most familiar with,” and “we don’t tailor the questions to the organization we’re hiring for because we want a uniform process for all TPMs.”
If you’re looking for an iTPM, asking about “the space that most people are most familiar with” (application software) is going to fail very talented infrastructure people who aren’t given an opportunity to showcase the talents you are supposedly hiring them for. When I did system design interviews for EC2 networking iTPMs at AWS, I was always focused on problems that were relevant to our org: an appreciation for the complexity of infrastructure, monitoring, reliability, failure modes and how to address them, scaling, etc. I never once asked somebody what kind of a database they’d use or why. It just wasn’t relevant. Besides, it was AWS and we used DynamoDB for storing everything that couldn’t be stuffed into S3 objects, which was the only other allowed solution. We weren’t a generic org, and we didn’t hire generic TPMs.
Why I didn’t get a recent job…
The program/tech review interview can be problematic as well. I don’t remember mine from AWS. I think it happened during my initial screen. At Stripe, the interviewer was happy to let me deep dive the load balancing infrastructure and control plane, and how I modified and optimized it to save Amazon a lot of money. He was less concerned with “what did you build” than he was with “prove that you’re technically adept.” It was fine that I was focused on cost containment in the infrastructure space so long as I could demonstrate that I really understood the space to a detailed technical level and used that technical knowledge to drive decisions and achieve my goals. He didn’t care that the things I had built in support of my program were either tools that enhanced our ability to operate more efficiently, or customer self-service tools that improved our customer experience and reduced our workload. He didn’t care that it wasn’t a cookie-cutter example of me building a new feature from scratch.
But that’s not always the case. I once interviewed with a company where the interviewer clearly had a script to follow and that script was more or less: “tell me about a piece of software you built start-to-finish, what was the problem, what features did you need to create, what did the software design look like and what were the tradeoffs?” He was neither an engineer nor a TPM nor familiar with infrastructure at all, despite being on the interview loop for a “core infrastructure TPM” role. He was looking for a good user story that defined the requirement, a good story of how I built something to fit the requirement, and some discussion of the technical tradeoffs and decisions made along the way. See the above video for the segment about user stories in infra and why they don’t work.
“I built and ran a program that improved infra utilization by 30%, saved AWS $42m in hard infra spending, and at least as much in soft and human costs during the time I was there (and much more in the two years since)” (and yeah, I had to have some software tools built to better enable/automate that but they were a tiny piece of the work done), isn’t something that fits neatly into that script, so showcasing my technical abilities, which is what this portion of the interview is usually about, was challenging and the one of the reasons I decided not to proceed further. (The other is that Zuckerberg is a psychopath, I had misgivings all along, and he said something particularly awful that week that forced me to look in the mirror and ask myself if I could ever face the people I cared about and say I worked for him. Sometimes the money isn’t the most important thing.)
As Einstein is often misquoted “if you judge a fish by its ability to climb a tree, it will live its whole life believing that it is stupid.” I don’t believe I’m stupid, but your hiring process may be missing the mark if you’re asking an iTPM to describe a standalone piece of software they built with little to no context. If you’re running infra at scale and want iTPMs, you need to filter for infra experience and all the contextual messiness that comes with it.
Final thoughts
This misunderstanding of iTPMs fails other people in other ways. My departure from AWS was due, at the root cause, to my manager hiring me into his team while on the assumption that all TPMs are sTPMs at their core. I can’t entirely blame him. That was his prior experience on the retail side of Amazon before moving to AWS. But it became quite clear over time that despite joining a team called “Compute, Infrastructure and Operations” his expectation was that I had been an applications software person first, and that everything else was incidental. (In retrospect, our interview was far too brief, with far too little follow-up on both sides, so I’m at least 50% accountable for this miscommunication.) I made it work for a year, and layoffs made my departure relatively easy.
Since my departure, I’ve noticed that AWS is now listing “Infrastructure TPM” as a distinct role. I think this is a good thing. I’m guessing that my final experience there was not unique. AWS TPMs are a weird bunch even at Amazon, and most of us were very infrastructurally-oriented, managing a lot of the “fall between the cracks” things like capacity, onboarding, security, and other things that aren’t solved exclusively by building a piece of software. My colleagues had backgrounds in network engineering, systems engineering, hardware integration and a variety of other non-software roles. That’s not to say we didn’t or couldn’t grow into software, as that was our core product and a natural direction to go in no matter where you came from. One of my colleagues has gone on to be a software development manager for S3 (though, even that role is highly infrastructural, as he manages development of a handful of services that will only ever be called from within other parts of S3). Two others are now TPMs in customer-facing product orgs at software companies.
At AWS, some people in our organizational TPM group used the terms “breadth TPMs” and “depth TPMs,” with most TPMs being “breadth” and me, the one who moved to billing from an infra-focused team, as the “depth” weirdo. I dislike this terminology as in my opinion all TPMs need to have breadth. I do like sTPM vs iTPM, with the difference being where your breadth is focused. Most TPMs are sTPMs and most of what you see written about the field focuses on them. sTPMs will typically have breadth across their SW engineering and product organizations, while iTPMs will have less breadth across the application and possibly business environment and instead reach across the various layers of the stack and the organizations that enable it. At our best, we abstract away as much as possible, so our sTPM brethren and their teams don’t need to know about it at all and can focus on what they do best.
We’re weird and that’s OK.
For more on a related topic, see my next post about Additive vs. Reductive TPMs