What Ahrefs might have done, and what finops has in common with bank robbery
I wrapped my previous post saying:
In a follow up post, I’ll consider what a parellel-universe Ahrefs in a different reality timeline might have done in the cloud. I’ll look beyond the simplistic “we’ll run our existing application architecture on somebody else’s hardware” and see how much the needle might theoretically be moved.
Sutton’s Law

When asked why he robbed banks, bank robber Willie Sutton is said to have responded: “Because that’s where the money is.”
One of my early managers used Willie’s purported words to explain why he would cut big programs to fund new things rather than smaller and less impactful ones. Sure, you could cut a bunch of small things down to nothing, he’d explain, but that would still not pay for a new large program. You have to go where the money is.
When looking at costs, it’s important to consider where the money is, because that’s generally where you’re going to be able to save the most. As I reconsidered my SCaLE presentation on anti-patterns, one of the underlying (or maybe overlaying) meta-patterns is “focusing on the wrong thing.” The wrong thing is the thing that doesn’t cost much to begin with. Optimizing something that you aren’t spending much money on is a low-priority problem.
This is why most of the criticism of Ahrefs was fundamentally wrong. Most of it was focused on optimizing compute. But look at Ahref’s own estimation of what they would spend per-server if they were on AWS:
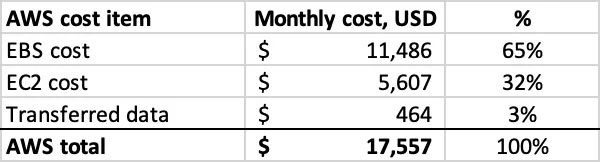
See that 65% item? It’s EBS, or Elastic Block Store. It’s storage, not compute.
That’s where the money is.
A thought experiment
Any solution has to deal with that outsized storage bill. There’s no way you can even get close without dealing with it. Dealing with it probably means completely rethinking how the data is stored, which will mean changing how the application that stores and reads it works, which will likely mean a complete ground-up redesign.
It will likely mean a massive cultural shift as well. Such an alternate-timeline Ahrefs would have to be a company that doesn’t build it’s own database, and would likely have to spend less time obsessing over the pros and cons of obscure programming languages and development environments, in favor of things that work best with the cloud infrastructure. From a tech perspective (and beyond, due to Conway’s Law), it would be a completely different company. So I’m not proposing any of this seriously.
This is a “what if” thought experiment, not a real suggestion of re-architecture. I don’t know enough about how Ahrefs works internally to suggest that, but I like considering what might be possible, given what little I do know. Thinking through “what if” is a great way to learn, if nothing else.
Ahrefs isn’t too open about the details of their internal architecture, but one online discussion did reveal that they had “their own database” that is a key-value store, with as much as 600PB of storage available.
Whenever I hear about data at that scale on AWS, I think of S3, which is an object store, and is successfully used for storing massive key-value data. On a byte-for-byte basis it can be as much as an order of magnitude cheaper than any AWS storage alternative. But S3 is an object store not a filesystem. Common database managers can’t run with S3 as the storage layer, which is why it would have to be a completely different design, starting from different assumptions, and I’m assuming for the purpose of this exercise that it could work at all.
So, how much would it cost if we could use the cheapest AWS storage rather than a substantially more expensive option?
The AWS pricing calculator can be helpful here. Each of the Ahrefs servers is said to have 120TB of storage (actually, 2×120 with everything replicated). In S3 there is no notion of “available storage.” You pay for storage used, so to keep the numbers simple, I’m going to assume that each 120TB server actually stores 100TB. (This is probably high unless they like going into more dangerous utilization levels than I do.)
Storing 100TB per month in S3 currently costs $2304 in my favorite region (us-west-2). S3 also charges for post and get transactions and this is where any estimation based on a purely theoretical scenario is going to get tricky. We know from the data they publish that Ahrefs updates metrics for about 2% of all pages they index every day, or about 60% every month. I’m going to make some wild ass guesses about file sizes and how often each file might need to be overwritten with new. For 100TB of data, I’ll allow for 200B post requests every month and another other 500B get requests. That should be enough to write the entire database used by that server more than once, and to read it several times.
What the calculator says is:
S3 Standard storage: 100 TB per month x 1024 GB in a TB = 102400 GB per month
Tiered price for: 102,400 GB
51,200 GB x 0.023 USD = 1,177.60 USD
51,200 GB x 0.022 USD = 1,126.40 USD
Total tier cost: 1,177.60 USD + 1,126.40 USD =
2,304.00 USD (S3 Standard storage cost)
200,000,000 PUT requests for S3 Standard Storage x 0.000005 USD per request =
1,000.00 USD (S3 Standard PUT requests cost)
500,000,000 GET requests in a month x 0.0000004 USD per request =
200.00 USD (S3 Standard GET requests cost)
2,304 USD + 200.00 USD + 1,000.00 USD = 3,504.00 USD
S3 Standard cost (monthly): 3,504.00 USD
That’s a lot less than $11,486, and would bring the total per server down to $9,575 from over $17k. Still not competitive with their in-house cost of $1,550, but better.
Add in a typical use of savings plans and an appropriate enterprise discount and the cost would likely be in the $4,500 range. Still noncompetitive. (Assuming a 62% savings on compute, using RIs/savings plans, and an enterprise discount on everything of 40%.)
And keep in mind that even this is bare-bones storage, and doesn’t include a lot of the “glue” (or even, the AWS Glue) that you would need to make it all work. I don’t know what other pieces already exist in their front-end to make use of their current data, but I’m guessing there’s something and that the costs aren’t negligible.
Which is why, at the top, I said Ahrefs made the right business decision. My thought experiment was designed to make the most favorable assumptions I could without laughing at myself and it’s still off by about 4x. It’s not the billion dollar clickbait number, but leaving the headline number aside, you can’t argue with their business case.
[Note: In my previous comment, I mentioned that if they really wanted to compare apples-to-apples, they would not use “EC2 instance + external storage.” AWS offers “I” instances that include the attached NVME storage they crave, and that would be a better comparison. For the purposes of this analysis, I started from their baseline case. Going beyond that would be interesting, but beyond what I’m willing to do for a blog post.]
What about change?
Ahref’s logic assumes the hardware doesn’t need to change. Every one of those servers is good for (presumably) a normal life of about 6 years. [That’s the number AWS uses. I’m going to go with the assumption that nobody else is going to get better server life.]
What if your requirements change frequently, in ways that demand changes to the underlying infrastructure? How often would the infrastructure need to change to make this latest version of Ahref’s presumed costs even remotely competitive.
Again, starting from 6 year life cycle. Ahref’s assumes one of those servers costs $1550 per month. Effectively it’s 25% of the cost of the best case AWS solution I can come up with. But part of that (about $500) is the operating cost, which would presumably remain stable even if the hardware portion was thrown away and replaced.
I’m doing some very “back of envelope” thinking here. But that means you need to get your monthly hardware cost up to about $4,500 to bring it in line with real-world AWS costs. That would mean you’re replacing the hardware 4.2x every 6 years. About every 17 months. Add in some extra costs for the labor of doing this, and some “overlap” time during which old and new hardware are both active for a transition, and maybe it’s 18 months. Even that is based on the assumption that you can’t reuse anything and can’t resell anything, which is absurd. So, even if your needs change relatively frequently, there’s no way the numbers pencil out in AWS’s favor.
The larger point
In my discussion of cloud strategy at SCaLE I didn’t explictly call out one key point: architecting for the cloud is fundamentally different from architecting for your own hardware.
The purpose of technology isn’t to allow us to construct cool architectures, or to pontificate about the minor pros and cons of various programming languages. It’s to solve real business problems. “Which pile of stuff is cheapest?” is rarely the right question. “What are the different options for solving my business problem, and what combination of software architecture + pile of stuff will support the best solution at the lowest cost?” is better. Recognizing that “best solution” and “lowest cost” are often in conflict is necessary too. Change the pile of stuff available, and the software architecture must change to accommodate. Hold the software architecture stable (and assume it won’t need to change over time) and it will almost always be a mistake to change your infrastructure environment, or to pay a premium for the ability to change it.
When deciding if something makes sense for the cloud or not you need to ask two questions: what would the application look like in each environment — recognizing that the two applications may need to be dissimilar even as they deliver similar functionality! — and then what are the costs and benefits to each potential direction. An application designed around hardware that you configure and control will probably be pretty miserable when lifted-and-shifted to the cloud. But the opposite is true. An application designed to use the capabilities of cloud services is going to be pretty awful if you have to migrate it to an owned-hardware environment. When we moved off mainframes we did not hold the software architecture constant. We re-imagined it in a way that made the best use of the new infrastructure. You have to do the same if you want to get the best use of the cloud too.
I continue to disagree with Ahref’s numbers and approach to considering the problem, even while agreeing with their conclusion.