Udacity Deep Learning Nanodegree – Part II
I’m into the third segment of the Udacity Deep Learning program, which deals with convolutional neural networks. But the past couple of days it’s become clear that there were a some topics from the previous segment (neural networks), that I didn’t fully understand and wanted to explore further. I left last week’s PyData Meetup with more questions than answers. Questions like “why does that neural net I just wrote perform the way it does?” So, with a couple of weeks left until the next project is due, I decided to go back and revisit the second half of the neural networks topic before moving forward.
But First, it’s GPU time!
[Warning: This will be horribly nerdy.]
There’s a GTX 1070 in the workstation I’ve been working with, but I had not found the time to set things up so it would run correctly from TensorFlow within Jupyter Notebook, which is where most of my work is taking place. TensorFlow is quirky, Jupyter Notebook is quirky, and nVidia drivers sometimes really suck, so it’s no surprise that the combination was more than I wanted to deal with last week and I just forged ahead using standard CPU power to train my small neural nets. But I did want to get it right.
The first thing that occured to me is that while I have a couple of Conda environments that are running TensorFlow for scripting, I don’t quite recall what I did to get them that way. So one thing I’ve done carefully this time is document exactly what is the minimum setup for me to have a working TF environment that is appropriate to my needs. I’ll clean up my notes and publish them tomorrow, but here is a writeup from my friend Derek about how he approaches a minimal TF install in his business. His purpose and need is different from mine, but it’s a useful guide for how to track things that I can aspire to. He has an entire blog full of such cheat-sheets.
There were a whole bunch of pieces including Conda and the nVidia drivers that needed to be updated to current. Reinstallation of TF was not necessary, but I did need to remind myself to update the $PATH variable in the environment. And to get it working right in Jupyter, I also had to update $LD_LIBRARY_PATH. Also, sometime in the past year the vanilla version of Jupyter that installs with Conda has been slimmed down so you can no longer select which environment you want to work in. (Or this may be related to the fact that I’ve moved from Python 2.7 to 3.5. Or both.) No matter where you start it from, it will use your default Anaconda setup. To get around that you have to install a bunch of Jupyter extensions, then remember to select the environment you want. Fortunately, once you’ve done that once, it will remember it.
In a weird quirk, the Chrome browser reported intermittent problems with the nVidia driver, and while a driver update solved the problem, I found myself eventually usuing FireFox with Jupyter, which seems to just work.
After a couple of hours of mucking about, I got this all right, and for a change I carefully documented it. It’s a habit I fell out of in the years when I had professional systems administrators and others to support me and provide “company standard” setups. Now that I’m my own sysadmin again, I have to get back in the habit of documenting every setting so I can repeat it next week. [Update: “recipe” for TensorFlow/CUDA/GPU setup is now done and available.]
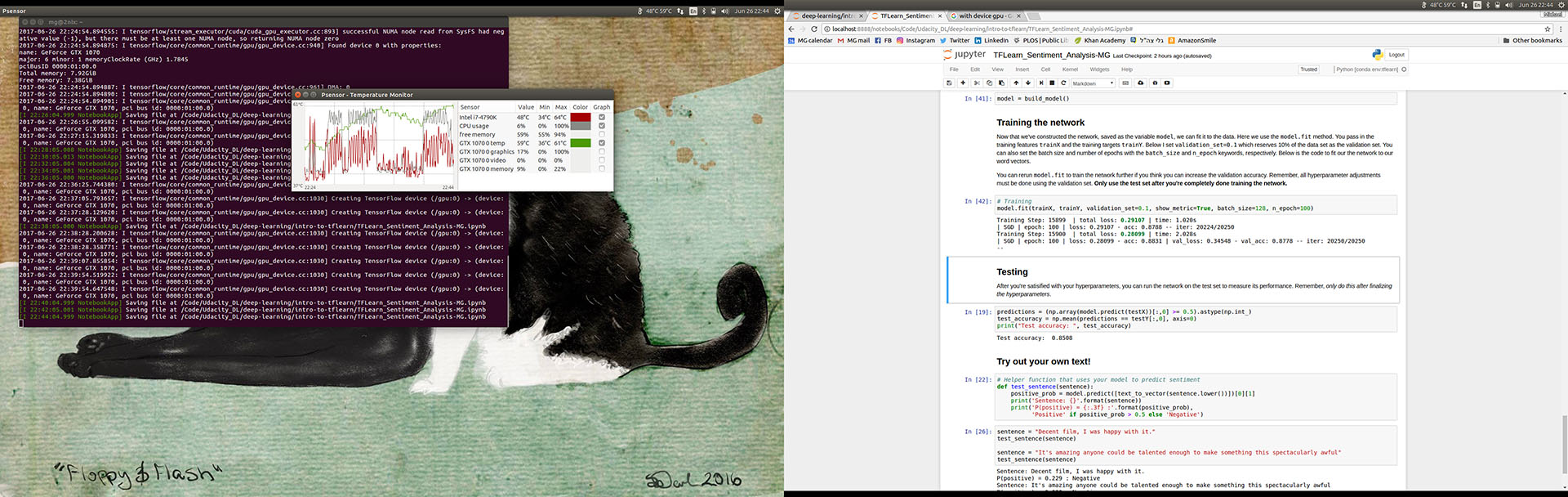
I was quite happy to see that the workload is obviously well-distributed between the CPU and GPU, as are the skyrocketing temperatures. One thing that’s obvious from my experimentation is that it’s necessary to optimize how the two are used.
TFLearn and Neural Nets
The exercises I worked on today which involved text sentiment analysis (the standard movie review database everybody uses) and character recognition (using MNINST). I’ve seen and used both of these before but this time I stopped and let myself play around with the parameters for network creation to attempt to really optimize the result. There were no huge surprises as both of these have been done to death, but they’re a typical rite-of-passage and well worth exploring in a way that goes beyond “tweak the code in this notebook and see what you find.”
To work with them, the class uses the TFLearn package, which acts as a wrapper for TensorFlow and simplifies creating the neural net. It’s fairly simple matter to just tell TFLearn what layers you want, how many nodes you want to have in each of them, and what types of activation functions to use for each. It greatly simplifies building the network compared to running it by hand as I did in the previous section.
One thing that’s obvious from my observation of system stress and CPU/GPU utilization while this exercise ran is that the downside to making this into such a black box is that there are inefficient handoffs between the CPU/main memory and GPU between training epochs. Since my dataset and model are both relatively small, the back-and-forth chews up much of the time that is saved by using the GPU. This isn’t an unknown issue and there are code optimizations possible. However, the real solution is to use a GPU where it makes sense to, usually with much larger datasets and more complex networks where it can do what it’s good at: chewing through trillions of floating point operations one after another without having to wait on anything else.
Still, from a hardware geek’s perspective, watching the system and temperature monitors as the model ran — first on CPU only, then with the GPU — was enlightening. The CPU temps remained lower overall and the GPU stabilized in a high but safe zone.
Skater will wait
The original plan was to apply Skater — one of the tools I learned about last week — to the model to see what it could tell me about what the model was really looking at. That will have to wait. As I spent much of the afternoon tuning my system and then tuning the model, that will have to wait.